the mfs system -------------- this section discusses one of the more powerful features of dlxs xpat, the mfs system (multi-file system).
THE MFS SYSTEM
--------------
This section discusses one of the more powerful features of DLXS XPAT,
the MFS System (Multi-File System). If you are setting up a text
database for the first time, you can read this introduction and then
skip to Chapter 3. Afterwards, when you are more familiar with DLXS
XPAT, you can return to this section and finish reading it.
The MFS (Multi-File/Filter Support) system is a module that all DLXS
XPAT index-building and search programs use to access the text of MFS
databases. The MFS system allows the text of the database to exist as
a group of files in any number of directories on disk. In addition,
the MFS system allows these files to be in many different data formats
(e.g., native word-processor files, spreadsheet files, relational
database files, ASCII files, etc.). The MFS system supports this
variety of data formats by using afilter system. This filter system is
needed because of the difference between the data formats of the files
on disk and the data formats required by the DLXS XPAT programs. For
example, most word-processor files consist of the text of the document
combined with the word-processor's formatting commands. In contrast,
the DLXS XPAT programs require just the text, without the formatting
commands. The data filters in the MFS system "filter" the
word-processor data to eliminate the formatting commands, passing the
remaining text to the indexing and search programs.
The MFS System concatenates the filtered texts of all the files in the
database together to form a "virtual text" file. The indexing programs
then build their indices on this virtual text file, and the search
programs effectively perform searches on this file. Note that the
entire virtual text never actually exists physically on disk; the MFS
system generates the segments that the indexing and searching programs
require.
In order to provide the required level of filter flexibility, the MFS
system combines several filters intofilter chains. A filter chain is a
sequence of filters that are linked together in series so that the
output of one filter is the input of the next. The first filter in the
chain reads the raw file on the disk, while the last filter sends its
output to the indexing and search programs.
The MFS configuration for most data formats consists of two filters.
The first filter is a word- processor filter that extracts the text
from a particular type of word-processor file. The second filter is
the meta filter, which DLXS XPAT supplies. The meta filter creates a
basic tagged structural framework around the text of each file.
Included in this meta-data is extra information that is associated
with the file, but which is not in the actual text of the file (e.g.,
the filename, the modification date, etc.). This basic two-filter
configuration is illustrated in Figure 2-5.
[need illustration]
Note: While most filter chains consist of this two-filter
configuration, the general filter chain mechanism can have any number
of filters. The only requirement is for each filter to be able to
process the output format of the previous filter in the chain. For
example, suppose the database consists of a group of encrypted,
compressed word-processor files. The filter chain might then consist
of a decryption filter, followed by a decompression filter, followed
by the word-processor filter, and ending with the meta filter.
The FastFind Index [shoved here temporarily by jpw]
The FastFind Index is a performance-enhancing, supplementary index for
the Main Index. The FastFind index is generally required for MFS
databases. This is especially true of MFS databases consisting
primarily of word-processor files. This is because the access to the
text is usually relatively slow since the text must be passed through
a filter system before the search engine can use it. This filtering
stage adds a significant time overhead (the MFS system is explained in
more detail in Section 2.2).
The FastFind Index consists of three files. These files are usually
named with the same prefix as the DD, and with the suffixes '. ffc',
'. ffi' and '. ffw'. These files are built by the patffiSO and
patffO50 programs, which are described in detail in Chapter 12.
The FastRegion Indices [shoved here temporarily by jpw]
The FastRegion Indices enhance the performance of search operations
that limit string searches to specific regions. One FastRegion Index
is built for each region in the database for which search performance
needs to be enhanced. If a FastRegion Index is built for a particular
region, the time is greatly reduced for search operations that find
occurrences of a search string in that region. You would normally
build FastRegion Indices for the regions that will be used the most in
database searches (e.g., Title, Summary or Date fields).
Each FastRegion Index consists of one file. This file is named with
the prefix set to the name of the region it was built for, and with
the suffix '. fri'. This file is built by the patfr50 program. This
program is described in detail in Section 12.3.5.
The FileMap [shoved here temporarily by jpw]
The FileMap is a central component of MFS databases. It contains one
entry for each file that is a part of the database. Each entry
contains supplementary information related to the corresponding file.
In essence, the FileMap is a sort of directory for all the files in
the database.
The FileMap consists of three files. These files are usually named
with the same prefix as the DD, and with the suffixes '. fmp', '. xmp'
and '. Imp'. These files are built by the mfsbld50 program, which is
described in detail in Section 12.3.1.
Meta Filter Details
As mentioned above, the meta filter takes the text from the previous
filter in the chain (usually the word-processor filter) and wraps
extra tagged data fields around this text. These fields are called
meta-fields. The meta-fields contain system-related data, such as the
text file's modification date and filename. In addition, the
meta-fields can also contain user-defined information that is
associated with the text file, such as the text of a Headline, Title
or Summary for the file. This user-defined information is called user
meta-data.
The following example illustrates how the different components all fit
together. As you follow this example, refer to Figure 2-5.
Assume a word-processor file exists on disk. Also assume that when the
data in that word-processor file is passed through Filter I (in Figure
2-5) the following line of text is the result:
This is the text component of a word processor file
Next, assume that the following line is the user meta-data for the
file (the details of how the user meta-data is incorporated into the
FileMap is covered in Section 12.3.1):
This is the headline for the word processor file
Finally, assume that the file's name is 'wpf ile. doc', and that it
was last modified on March 21, 1993 at 10:34 am. Then the following
lines would be the output of the meta filter (Filter 2 in Figure 2-5):
headline for the word processor file
the text component of a word processor file
Note: In the real output there would be no newlines. The actual text
of the file is contained between the
The majority of the above fields are self-explanatory. The only field
that may not be familiar is the
discussed in Section 1.2.3.
The meta filter is required in the filter chains for two main reasons.
The first is that it provides a structural framework around the text
of the file. This framework is necessary because the powerful
structure operations that the search engine supports require some form
of explicit structural markup in the text (e.g., start and end tags
around different structural elements, such as the file and the
Headlines). In MFS databases, the actual filtered text that is
produced by the word-processor filter usually contains little or no
structural markup. The meta filter adds structure to this raw text by
providing a consistent form of structural markup (i.e., the above
perform structural operations at the file level in a consistent manner
across all MFS databases.
The second reason for the meta filter is that it provides rapid access
to the meta-fields that it generates. This feature is important
because part of the operation of most user interfaces involves the
construction of summary lists for the results of queries. These
summary lists must be built quickly to ensure fast response times.
Each line in the summary list usually contains information that allows
users to either identify the corresponding file or the contents of the
file. This task can usually be facilitated by providing the user with
the filename, Title, Headline or Summary. The meta filter meets the
requirement for such fast access by getting all the information it
needs from the FileMap (the FileMap, as described in Section 2.1.6, is
essentially a directory of all the files in the database).
You should recognize that the user meta-data for each file can be any
segment of text. While the user meta-data in the above example
consisted of a simple line of text, it may just as easily consist of a
number of tagged fields. The only consideration in using it this way
is that the longer the size of the user meta-data, the bigger the
FileMap files.
As an example, assume that the database consists of a group of image
files that were scanned from a paper document. Also assume that the
image of each page is in a file by itself. Assume that the user
meta-data must include three fields for each file. These are the Title
of the page (assume this can be extracted somehow), the page number,
and a link number to, say, the next page that deals with the same
subject. Then, the user meta-data for a given file might consist of
the following line (
field, and is the link field):
Assume the first filter in the filter chain is some sort of OCR
filter, and that the output of that filter for the above page is the
following line of text:
Some great document whose next page is on page 354
Then, the output of the meta filter would be something like the
following:
< /OTTime>OTFieldsSize>57< /OTFieldsSize>
headline text< /HL>
next page is on page 354
Note: The user meta-data text is copied verbatim into the meta filter
output (tags and all). The region- building program can then build
regions on these user meta-data tags, with the same mechanism that is
used to build other regions. The only limitation is that you should
not use any of the following tags in your user meta-data, as they are
the meta field tags and are reserved for use by the DLXS XPAT system:
Database Views
The filter chain mechanism described in the previous section
essentially provides a view of the database. A view is characterized
by the transformation that its filter chain performs. For example, the
above discussion described the filter chain for a view of the
database's text. That view can be contrasted with a different view
that, for instance, retains some or all of the word processing
commands in the file.
The text view is appropriate for indexing purposes. However, it may
not be appropriate for operations such as text previewing, since
accurate reproduction of the original document is much easier when the
original formatting commands are available. The MFS system supports
three different database views to handle the different requirements of
the different parts of the text DBMS. These views are the Search View,
the Display View and the Raw View.
The Search View was discussed above and is depicted in Figure 2-5.
This view provides a window into the text of each file in the
database, along with the meta data associated with that file. The
indices are built upon this view and the searches are performed on
this view.
The Display View is intended to provide a view of the database that is
suitable for display purposes. The Display View exists because the
data in the Search View consists of just the text; none of the
formatting commands are retained. The text, alone, may not be
appropriate for viewing programs because it will likely not contain
enough information to recreate the original formatting.
One important point to note about the Display View is that the actual
format of the data coming out of this view does not need to be the
same as the original data file. For example, consider a filter chain
that converts the word-processor data into a stream of typesetting
commands for a particular typesetting system. The user interface
program can then send that data stream to a viewer program that
understands the typesetting language. As long as filters exist that
can transform all the different data formats in the database into a
single typesetting language, the same viewer program can be used to
view all the files of the database.
Another example of the Display View is a filter chain that does not
perform any transformations at all (i.e., which passes the raw
word-processor data to the viewer program). In that case, the
word-processor program itself could be used as the viewer. This
solution has the advantage of not requiring any intermediate
transformation filter, but has the disadvantage of requiring a
separate viewer program on the screen for each different data file
format in the database, which can lead to a cluttered screen.
One solution is a combination of the above methods, involving a small
number of viewer programs to support a wide variety of data formats.
In such systems, each viewer program may have its own Display View
data format. Because of this, the user interface needs some way of
identifying which data format is currently being sent so it can route
that data to the correct viewer program. This requirement is handled
by the Display Format label.
The Display Format label is a short string that uniquely identifies
each Display View data format. The Display Format label for each
different type of file is defined at index building time. The user
interface configuration parameters must also be setup to direct the
data for each label to the correct viewer. This user interface viewer
configuration is covered in the DLXS XPATQuery Configuration. The
Display Format label is generated by the meta filter, which places it
in the
have to look in that field to determine the format of each file's
Display View data.
One final point to note about the Display View is that its filter
chain should always end with the meta filter. The meta filter is
necessary because most user interfaces require some or all of the
information that it provides (such as the DisplayFormat label).
MFS System Summary
The MFS system is one of the subsystems that provides the flexibility
of DLXS XPAT. The MFS system allows the source data to (1) be
distributed over many files in many directories and (2) be in a
variety of file formats, including ASCII, native word-processor,
spreadsheet, database. etc. The MFS system uses filter chains to
dynamically "normalize" the various source file formats into a form
that DLXS XPAT can use. The configuration of MFS databases is
explained further in Chapter 3.
 INFORMATIONEN VERKÜNDUNGSBLATT DER FACHHOCHSCHULE LIPPE UND HÖXTER 30 JAHRGANG
INFORMATIONEN VERKÜNDUNGSBLATT DER FACHHOCHSCHULE LIPPE UND HÖXTER 30 JAHRGANG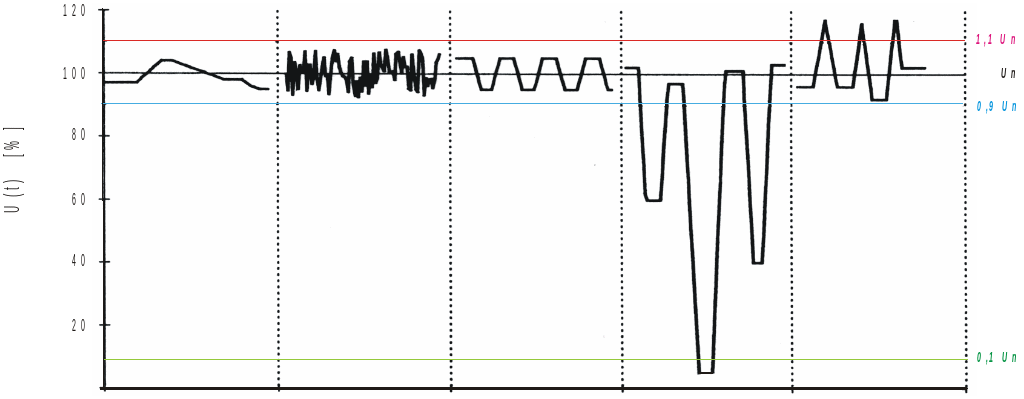 MATERIAŁY POGLĄDOWE SPORZĄDZONE NA BAZIE NIEAKTUALNYCH NORM ZABURZENIA WYSTĘPUJĄCE
MATERIAŁY POGLĄDOWE SPORZĄDZONE NA BAZIE NIEAKTUALNYCH NORM ZABURZENIA WYSTĘPUJĄCE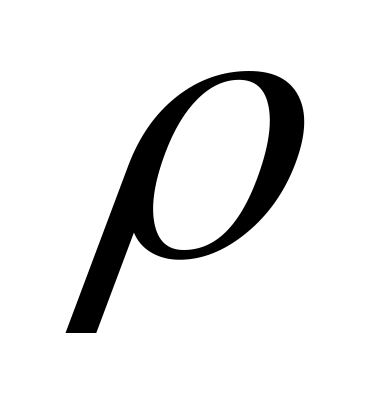 EJERCICIO 1 EN LA FIGURA SE REPRESENTA UNA TUBERÍA
EJERCICIO 1 EN LA FIGURA SE REPRESENTA UNA TUBERÍA FINANŠU INSTRUMENTU DĀRGMETĀLU UN NAUDAS KONTI PAKALPOJUMU CENRĀDIS FINANŠU
FINANŠU INSTRUMENTU DĀRGMETĀLU UN NAUDAS KONTI PAKALPOJUMU CENRĀDIS FINANŠU GENERAL LABOUR INSPECTORATE EXECUTIVE AGENCY 3 KNIAZ DONDUKOV BLVD
GENERAL LABOUR INSPECTORATE EXECUTIVE AGENCY 3 KNIAZ DONDUKOV BLVD JUVENTUD DEPORTES Y FESTEJOS Nº PÁG 1 1
JUVENTUD DEPORTES Y FESTEJOS Nº PÁG 1 1 GESTION DOCUMENTAL CODIGO GDCFO06 SOLICITUD CONSULTA DOCUMENTAL VERSION 3
GESTION DOCUMENTAL CODIGO GDCFO06 SOLICITUD CONSULTA DOCUMENTAL VERSION 3 Vortrag Umsetzung der Betriebssicherheitsverordnung aus Behördlicher Sicht Anforderungen der
Vortrag Umsetzung der Betriebssicherheitsverordnung aus Behördlicher Sicht Anforderungen der II TURNIEJ KARATE KYOKUSHIN O PUCHAR WÓJTA GMINY CHODEL
II TURNIEJ KARATE KYOKUSHIN O PUCHAR WÓJTA GMINY CHODEL F UERZAS MILITARES DE COLOMBIA ARMADA NACIONAL CONTROL INTERNO
F UERZAS MILITARES DE COLOMBIA ARMADA NACIONAL CONTROL INTERNO